

Enzyme: digesting even faster
In the previous post I shared information related to a project I’m spending my spare time on. It’s Enzyme, a new serializer for modern .NET. It’s not OSSed yet, but still, I wanted to share some finding and improvements (yep, it can be even better). In this post I’ll one optimization that I made that made Enzyme even faster.
ref struct Context
One of the ways to make things faster is to not allocate at all or use some kind of memory pooling. One of the ways to do the first is to use a struct (which is stack based) and share a ref to the variable. In this way, whole serialization process can enjoy sharing a state without allocating or leasing something from a pool. You could put anything in a context struct. To make it a bit more clear, let’s take at the following sample:
public struct MyContext
{
public int Offset;
public byte[] SomeMemory;
public string VeryImportantString;
}
With a struct like this you can pass ref MyContext to all the calls and enjoy passing a common state with just one parameter.
What’s wrong with context
This was my initial attempt in Enzyme. Then I noticed, that in majority of cases I don’t do any method calls (they are mostly manually inlined by writing lots of IL emit). This means, that I don’t have to use the context and I’m just fine with using a few variables instead. Depending on the number of fields in the context, using variables might be not good, but still, as I my context was small enough I wanted to try this approach.
The results were really good! Using pure locals and proper opcodes for loading them, made a real improvement in terms of the speed of Ezyme. I compare the results at the end.
Nullability
Initial, Enzyme was writing manifest, so me kind of a schema, as a first few bytes of the message. This required to mark fields that are null in a specific way. After changing the schema for a message and writing a part of the manifest before a field (something similar to what Google Protocol Buffers do) I was able to skip writing both field and a manifest if it was null. This less bytes to write and less bytes to read.
Benchmarking
I used a similar suite of benchmarks for these tests. Only the first one related to big object was altered a little bit. Let’s compare the results.
Array of strings - before & after optimizations
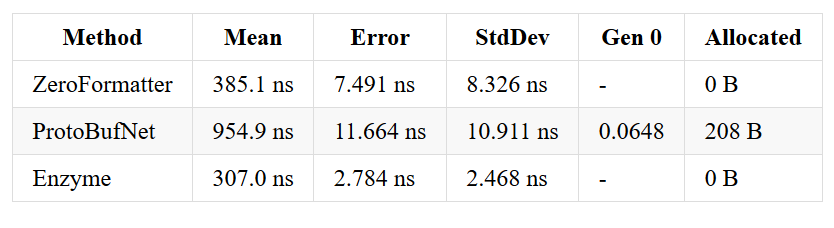
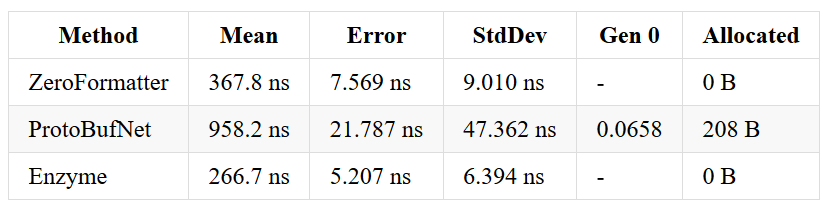
Array of ints - before & after optimizations
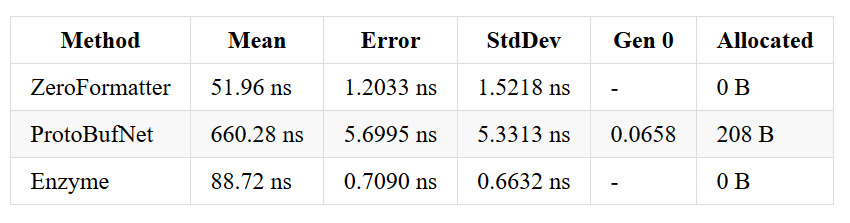
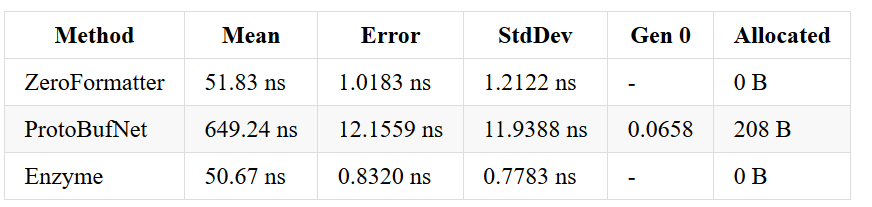
Array of Guids - before & after optimizations
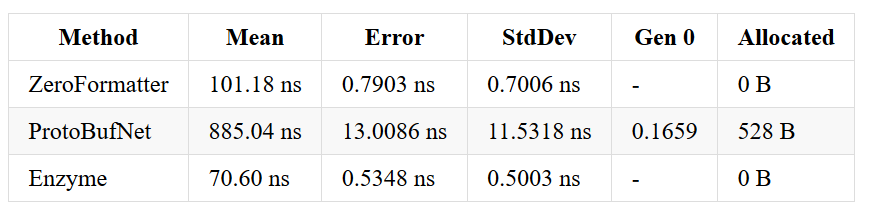
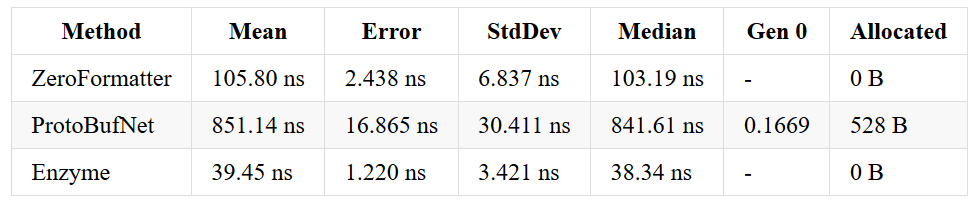
An object - before & after optimizations
This suite has been changed so do not compare absolute numbers. In the current version, the class contains a bool, an int, a string, a Guid and a nullable.
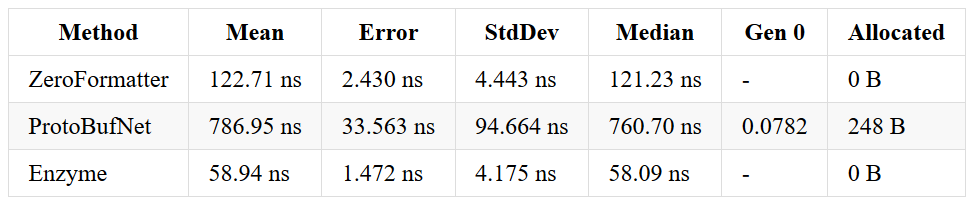
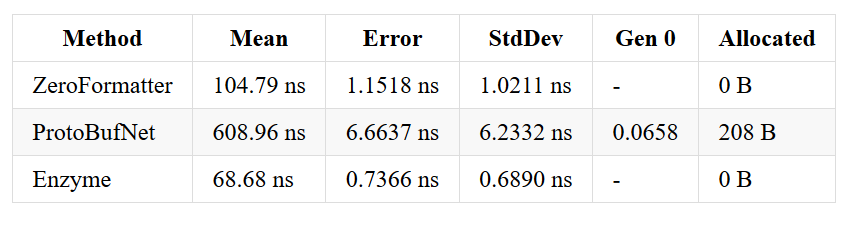
Results
I’m quite happy with the results so far, especially, with being able to write an encoded int array faster than ZeroFormatter. The Guid array result is a bit weird, as it’s just tooooo fast.
I’m working on a few more things right now, and I hope, that I’ll be able to share it soon.