

Async pump for better throughput in Azure
This post has been imported from my previous blog. I did my best to parse XML properly, but it might have some errors.
If you find one, send a Pull Request.
This post is followed up by http://blog.scooletz.com/2017/02/20/async-programming-model
TL;DR
Introducing async-await has changed a lot. Now, with some compiler’s help we’re able to squeeze out more throughput from our machines, which may lower costs and increase throughput. In this blog post we’ll push the boundaries even further by questioning the need of immediate awaiting on a task.
Background
The story behind this pattern is simple. I’m using a part of the Azure Storage Services, the page blob. It provides storage API targeted at random IO & page aligned reads and writes. This is a perfect solution for emulating disk IO (it’s used for VMs’ disks), but could be used in cases where you want to have ability to write to a file in Azure, under specific index. You can just read a page, modify it and write it back. If you’re interested in this topic, take a look at my talks, maybe we’ll meet during my presentation Keep Its Storage Simple Stupid.
Synchronous
It’s obvious that for reading/writing from Storage Services you want to use asyncified code. Using blocking calls like the one below freezes a thread, which considering the money you already pay, is not the best option. Remember, it’s the cloud and regular Storage Services are backed up by HDD disks. It might take a while. Still, let’s take a look at the sync version first. We’ll operate on a stream that has been opened from the blob.
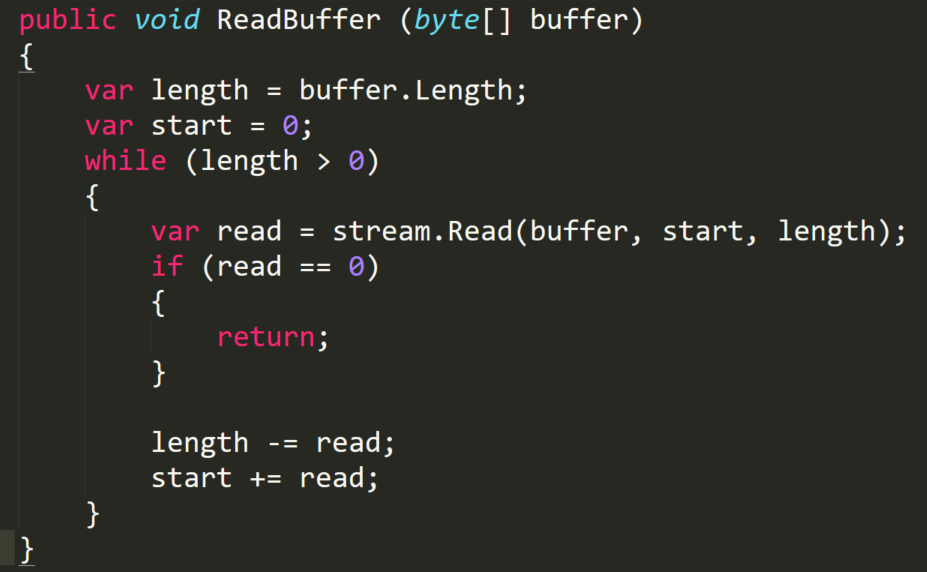
The method above reads the buffer from a stream. It dispatches a read after a read to fill the buffer.
Interested in async await, concurrency and you want to expand your knowledge?
Check out Async Expert! Together with Dotnetos I prepared something special for you!
Asynchronous
The async-ified version of this reader is not that different. It uses just async Task in its signature and awaits one the Read. We’ll have no blocking calls, leaving some spare CPU cycles for other operations.
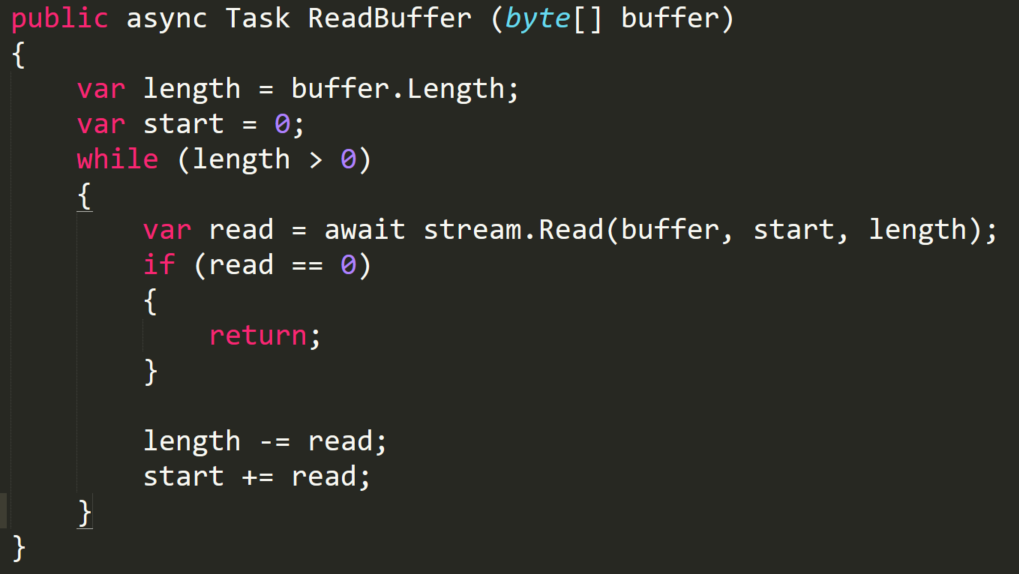
Asynchronous pump
In the last attempt, we need to ask what do we read this buffer for? In my case, that’s for scanning over its content. I need to read a page blob from a given position and scan/deserialize it in a C# code. I do not want to preserve the buffer. As soon as I read it, I can move on. It’s just about reading a log, nothing more. The second property of it is: entries in this log are aligned to pages, so are well aligned for reading. Can we modify the reading part then?
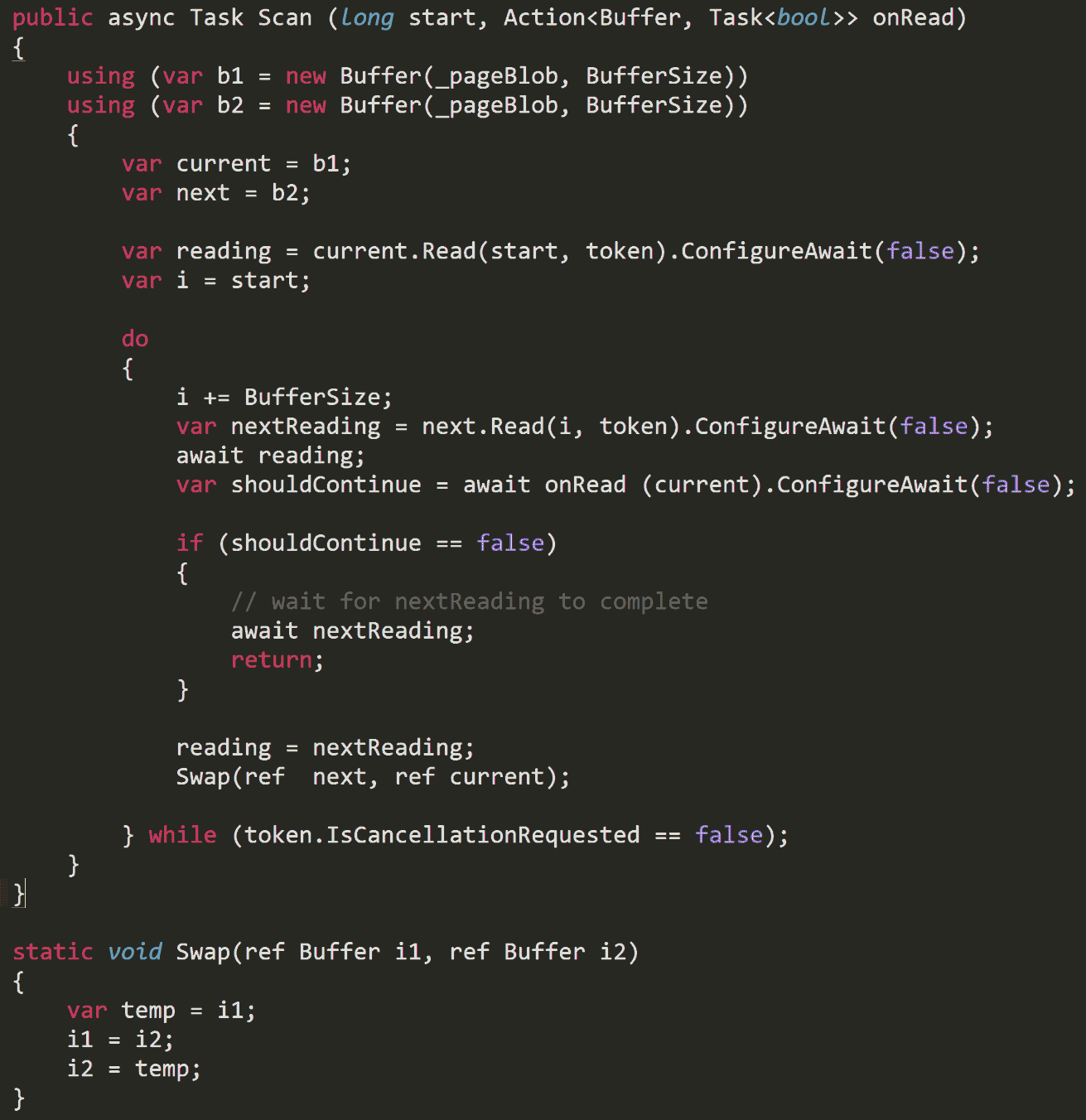
We could think of using two buffers/streams. Schedule a read in the first, then in a loop:
- schedule a read in the second
- await on the first
- swap firstsecond
- go to 1
If we used this algorithm, we’d have a higher probability of one operation being already ended and ready to be dispatched. This means that our algorithm, possibly, could work on prefetched data without any interruptions, having the data ready when it needs it. For sake of simplicity, the buffer array, ReadBuffer were closed in a simple helper class called Buffer.
Summary
Having something ready to be awaited does not mean that you should await it immediately. Using this two buffer approach can increase the throughput of your algorithm by ensuring that data are fetched before they are needed. Now it’s time for you to search for some pumping potential in your code!