

Thruster, building a not so fast memory pool
This post describes my work on trying to build a faster MemoryPool for .NET called Thruster. There are existing implementations, like the one provided by System.Memory or Kestrel, the new and shiny .NET web server. Let’s see what approached did I take and how it ended.
What is a MemoryPool
The memory pool is a great counterpart of the new Span<T> and Memory<T> that were brought by the mentioned System.Memory package. What Memory<T> does, is providing a consistent chunk of memory that one can access by obtaining it’s Span whenever they need. What Memory<T> does not provide is the memory lifecycle management. In other words, once you retrieve the memory from somewhere, there’s no way to release it. To do it, IMemoryOwner<T> was introduced. It’s a disposable construct that returns the owned memory to a pool, once it’s no longer needed. The simplest usage would look like this:
using (var owner = memoryPool.Rent(512))
{
await DoSomethingWithMemory(owner.Memory);
}
The first step is to request a memory chunk from the pool, which returns its owner. Next, operate on the memory obtained from the owner, and, eventually, dispose owner, which would return the memory to the pool. It’s worth to notice that you can use Memory<T> in asynchronous code. It’s a chunk of memory managed externally, by the owner, so it’s totally fine to do it.
Once we know what the memory pool is, let me share, what was the initial idea for the Thruster.
Circular buffers FTW
The initial idea for Thruster was to use a circular buffer for providing & reclaiming memory. A circular buffer, is a regular buffer, that uses an offsets of occupied and free positions to provide a never-ending-like array of items. You can think of then as head and tail where
- tail - follows the head pointing to the last free slot
- head - shows the last written slot
To keep our snake healthy, we must ensure that head never eats the tail. I’ve done it before in RampUp project, allowing multiple producers to claim memory and one consumer, to clean it up. I eagerly started implementing it and hit the wall during the memory reclamation. There was no single consumer as IMemoryOwner can be disposed from any thread. Another issue was that owners could be disposed in any order, leaving gaps in the ring. The third one, was that one could leave one memory owner alive and it could block the ring to move forward. I was not happy with this as the memory reclamation was getting harder and harder. I thought, that I started implementing my own Garbage Collector. I didn’t want to do it, so I dumped the idea of using the circular buffer altogether. This pool was meant to be a general pool, not something requiring disposing objects in a right order…
Per core pool
My second attempt was somewhat related on the default, shared implementation of IMemoryPool, that can be accessed via MemoryPool.Shared. What it does it delegates the memory management to an earlier construct the ArrayPool. The array pool has some interesting properties:
- it uses buckets of arrays depending on the which core you’re requesting the pool
- it uses buckets of arrays depending on the size you’re requesting
Effectively, when requesting an array, the call should go to the per CPU per size bucket returning the array in a fast manner. If this fails, another bucket of the next CPU is queried in a circular (again!) manner. This CPU affinity should bring some performance gains.
Padding
Some arrays and structures in Thruster are padded. Padding, in programming, describes extending memory size of a data structure to ensure that two different threads will be less likely to write values to the same CPU cache line size. If you can somewhat mitigate the possibility of cache line trashing, just ensure that values are aligned to 64bytes (128 for ARMs) and you’ll observe some performance gains when running a multi-threaded app.
Bitmasks
The idea that I came up with was using a long (64bits) per core and treat it as a bit mask. To claim it, one would need to obtain the value, and atomically swap it with the new one. The most important line is using the Interlocked.CompareExchange which allows atomic conditional swap of the value (think of it as UPDATE WHERE from SQL)
var result = Interlocked.CompareExchange(ref toUpdate,
newValue, oldValue);
To see the whole leasing, go here.
This approach has one drawback. Whenever a memory is leased or released it needs to touch the same long. This means same cache line and this means trashing CPU caches. Hey, you can’t get a free lunch, can you?
Benchmarks
After several trials I came up with two benchmarks. The first, that tries to rent memory in a single threaded environment, with nesting (two memories acquired) or without
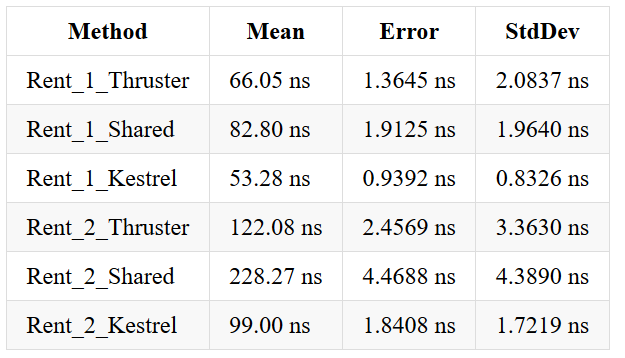
As you can see, Thruster is somewhat slower than Kestrel, but please remember, that Kestrel obtains only 4KB pages where Thruster can obtain (currently) any memory length (up to two hundreds of KB). This might change in the future.
The second benchmark was based on Kestrel pipe related benchmark. What Kestrel does is tries its memory pool against Pipelines using one or two threads.
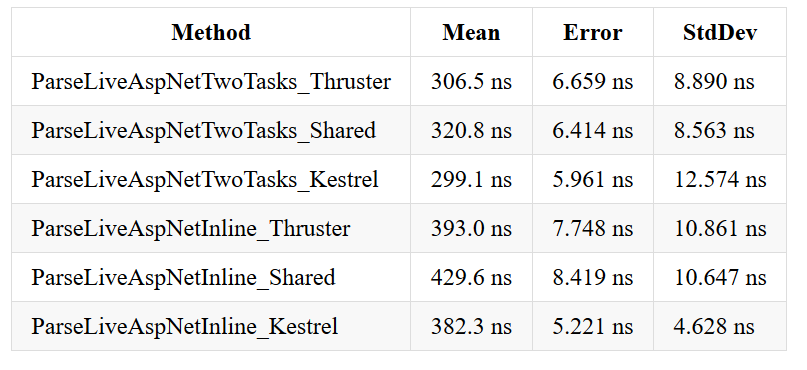
As you can see, in the second benchmark Thruster is not the fastest one as well.
Future
The only thing that comes to my mind right now is to try Kestrel, ConcurrentQueue-like approach, where leasing and releasing are separated in space. Also, using a fixed memory could help as there would be no non-continuous chunks of unreleased memory. The leasing would be as easy as obtaining an item from a concurrent queue.
Sources
If you want to learn more about all the tooling from this article here are some sources:
- 1024 cores - the must read for any concurrency adept with all the subpages!
- ConcurrentQueueSegment the structure behind the ConcurrentQuery from .NET showing how to implement a multi producer, multi consumer queue.
- SlabMemoryPool the memory pool behind Kestrel.
Summary
Writing a custom MemoryPool is a lot of fun. I’m giving Thruster a bit more time now, and, hopefully, it can be better some day.